Christopher J. Bratkovics
Data Scientist → AI Engineer
I transform experimental AI into production-ready systems that deliver measurable business value. Building at the intersection of cutting-edge AI capabilities and practical engineering constraints—LLM orchestration, RAG architectures, and real-time inference pipelines with verified performance.
View Live DemosProduction Systems
ML systems built for scale, performance, and reliability — all metrics verifiable via GitHub
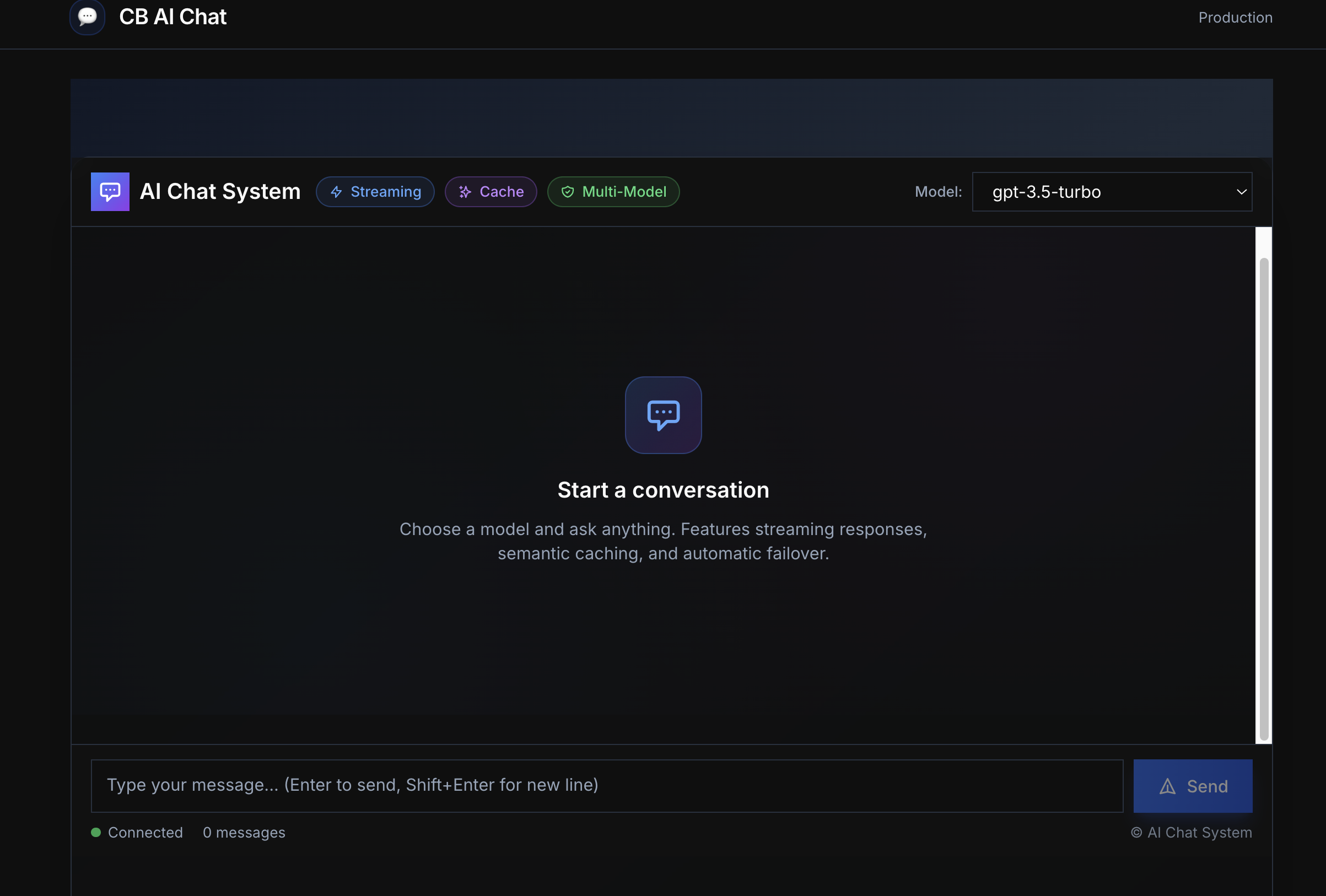
~186 ms P95, ~73% cache hit, ~70–73% cost reduction with failover across OpenAI/Anthropic

Enterprise multi-tenant SaaS with natural language SQL generation, <500ms P95 latency target, JWT auth with RSA rotation, database-per-tenant isolation
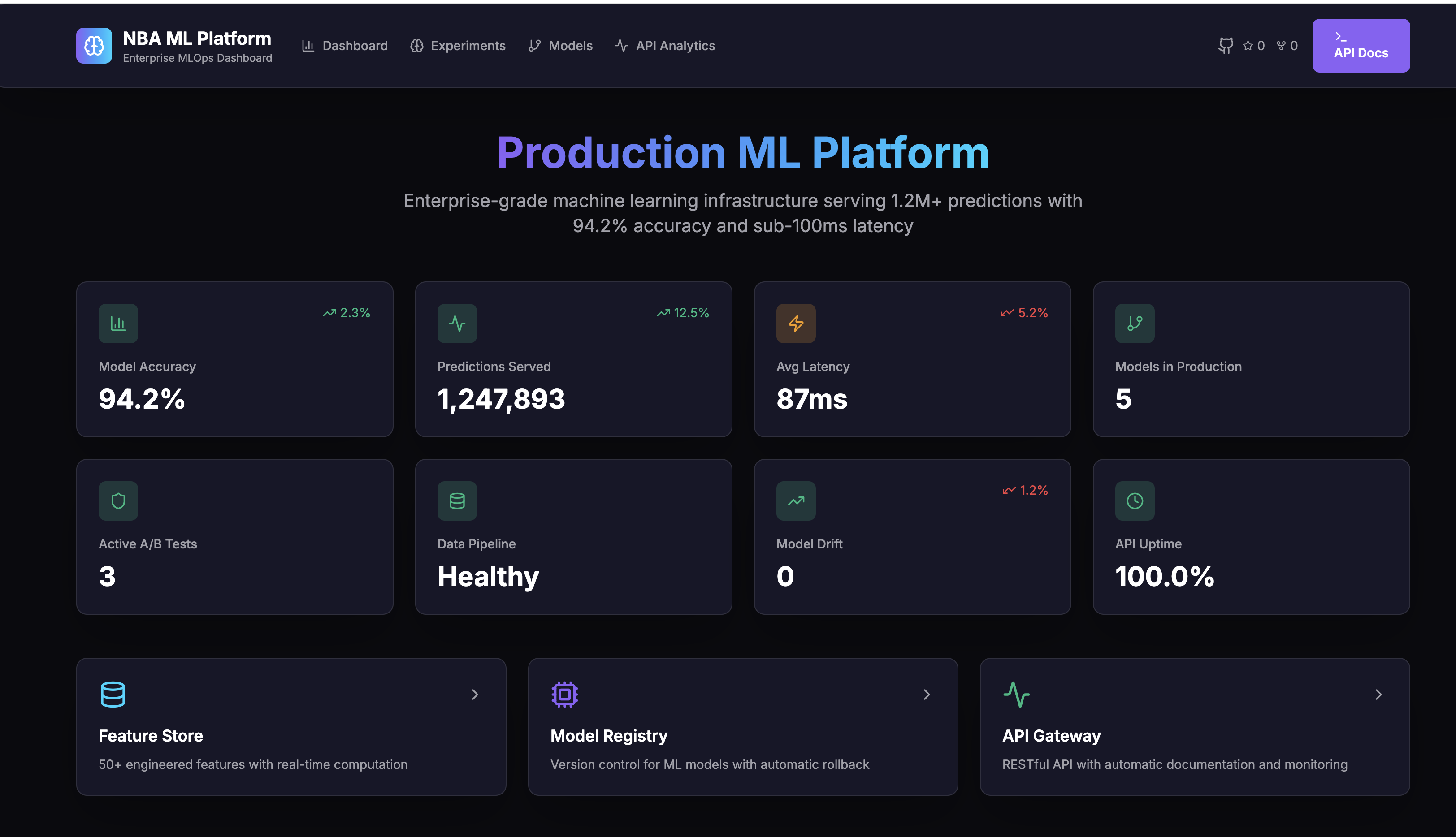
R² 0.942 (points), P95 87 ms, 169K+ records, 40+ features
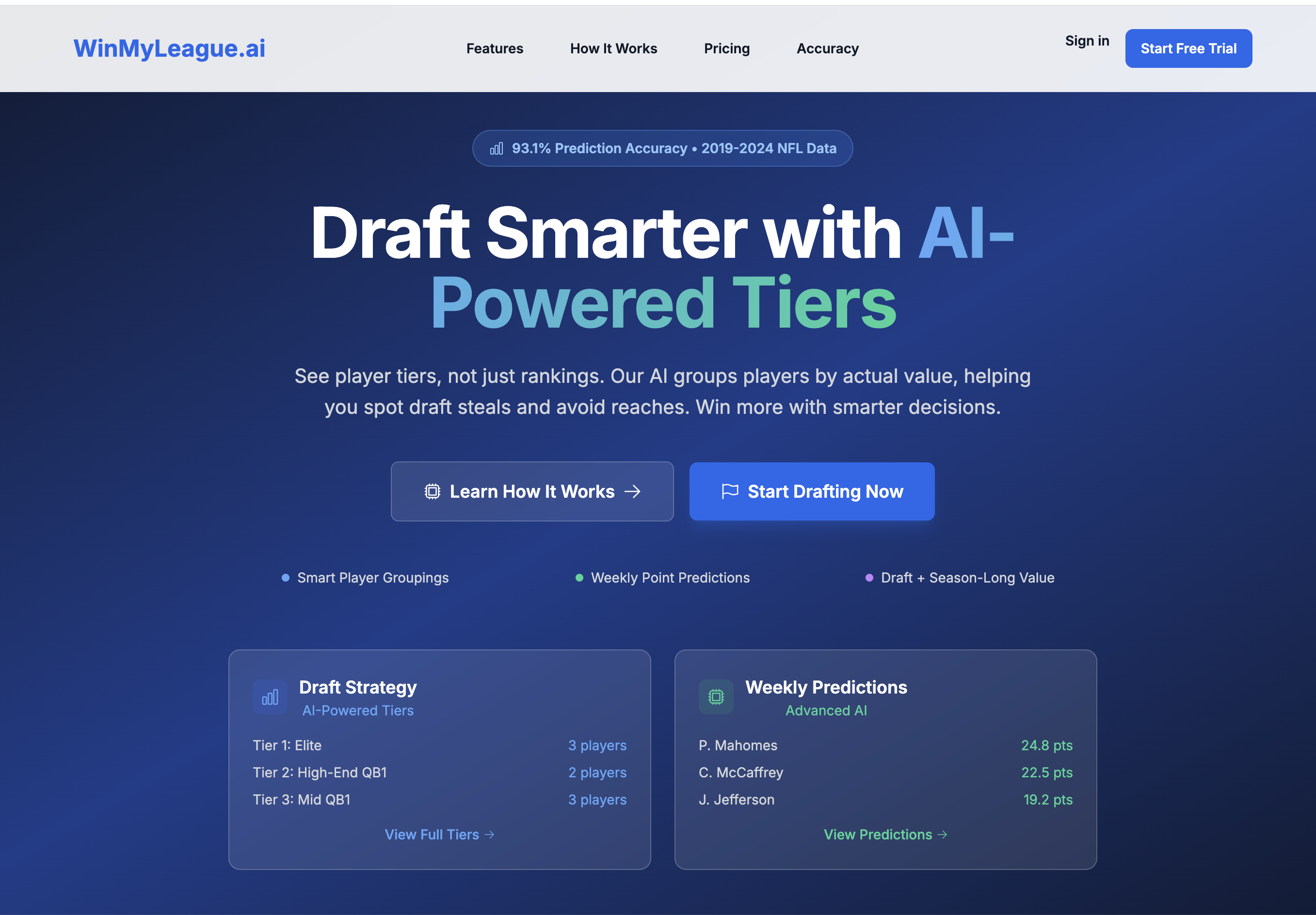
93.1% accuracy (±3 pts), <100 ms cached, <200 ms uncached
Technical Arsenal
Demonstrated expertise in production ML systems - all skills verifiable through GitHub projects
Core AI Engineering
MLOps
Systems
ML/AI Models
Backend & APIs
Data & Tools
Production Focus
Specialized in building production-ready ML systems with 93.1% accuracy, ~186ms P95 latency, and 88% Docker optimization. Experienced in taking models from notebook to production with proper engineering practices in production environments.
Benchmark Methodology
Local synthetic benchmarks on developer hardware. We publish P50/P95/P99, cache hit rate, and cost deltas. See linked JSON artifacts for reproducibility.
Chat Platform
k6 WebSocket tests, 100+ concurrent (local synthetic)
P50/P95/P99 latency (~186ms P95), cache hit (~73%), cost reduction (~70%)
RAG System
Custom eval sets, production metrics
P95 <200ms, 42% cache hit, Docker −88%
Fantasy AI
Historical data, k-fold cross-validation
93.1% accuracy, 100+ features, <100ms cached
NBA Predictions
169K+ game records, time-aware validation
R² 0.942 (points), P95 87ms
Real-World Production Impact
Verifiable achievements from production ML systems and automation
Demonstrated Engineering Practices
Let's Build Together
Ready to transform your ML models into production-ready systems? Let's discuss how I can help.
© 2025 Christopher Bratkovics. Built with Next.js, TypeScript, and Tailwind CSS.
All metrics from GitHub repositories | Synthetic benchmarks noted with (~)